
requests 설치
pip install requestspip 패키지 매니저를 통해서 requests라이브러리를 설치해줍니다.
requests.get()
import requests
res = requests.get('https://naver.com')
print('응답코드 :', res.status_code) # 200이면 정상requests.get(URL)을 통해서 해당 URL에 접근하여 크롤링을 할 수 있습니다.
그리고, 성공적으로 접근해서 HTML을 받아왔는지를 status_code에 표시하게 됩니다.
if res.status_code == requests.codes.ok:
print('정상입니다.')
else :
print('문제가 생겼습니다. [에러코드 ', res.status_code, ']')requests.codes.ok는 HTTP 상태코드에서 성공했을 때의 "200"값을 저장하고 있습니다.
따라서 위와같이 if문을 사용해서 URL에서 HTML을 성공적으로 받아왔을 경우의 로직을 동작할 수 있도록 하고
실패했을 때는 실패했을 때의 에러처리를 할 수 있습니다.
raise_for_status()
import requests
res = requests.get('https://naver.com')
res.raise_for_status()위에서 state code를 통해서 if문 처리한 것을 raise_for_status() 함수를 이용하면, 한줄로 만들 수 있습니다.
위의 함수는 성공적으로 접근에 성공했으르 때는 아무런 값도 반환하지 않지만, 실패했을 경우에는 에러를 반환합니다.
requests.text
import requests
res = requests.get('https://naver.com')
res.raise_for_status()
print(res.text)requests를 통해 URL에 접근에 성공하면 text로 값을 받아오기 때문에 값을 출력할 수 있습니다 .
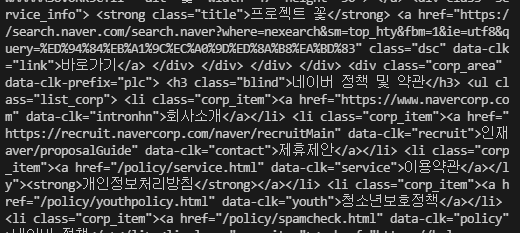
그러면, 위와같이 HTML을 볼 수 있고 이것을 이제 파일로 만들면
with open("myNaver.html", "w", encoding="utf-8") as f:
f.write(res.text)위의 코드를 통해서 받아온 res.text를 myNaver.html이라는 이름의 파일로 저장할 수 있습니다.
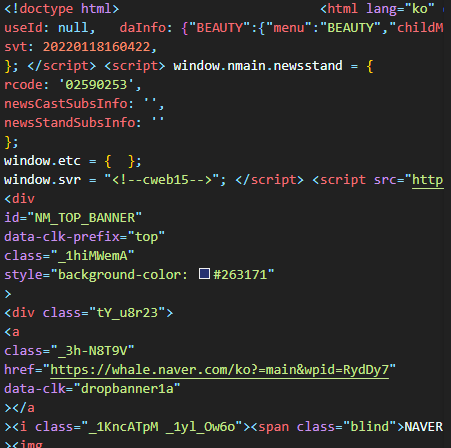
그러면, 성공적으로 파일이 생성된 것을 확인할 수 있습니다.
'IT 공부 > python' 카테고리의 다른 글
| [ Python ] 변수에 따른 함수를 실행시키고 싶은 경우 (getattr) (0) | 2022.02.28 |
|---|---|
| [ Python ] re 라이브러리를 이용해 '정규식' 사용하기 (0) | 2022.01.21 |
| [ Python ] 웹 스크래핑에 필요한 기본 IT지식 (XPath) (0) | 2022.01.18 |
| [ python ] django로 웹만들기 (0) | 2021.01.01 |
| [ python ] 자동 이메일 프로젝트 (0) | 2020.12.26 |