
Web Scraping
어느 웹사이트에서 원하는 정보를 가져오고 싶을 경우에 사용한다.
XPath
Scrabping을 할 때, 해당 url에는 많은 양에 태그들이 존재하기 때문에 비슷하고 겹치는 element가 존재한다
그 경우에, 어떤 것을 지칭하는지를 명확하게 하기 위해서 XPath를 사용한다.
/html/body/div/span/....
이런식으로 태그를 따라들어가야 하는데,
//*[@id="login"]
//*[@id="search_btn"]/span[2]
이렇게 간단하게 사용할 수 있다.
/는 현재 위치하는 것으로부터 한단계 아래있는 곳을 의미
//는 현재 위치로부터 모든 하위 엘리먼트를 의미
*은 엘리먼트 이름 상관없이 전부를 의미한다.
requests
pip install requests
우선 requests를 사용하기 위해서는 package를 설치해야 한다.
resquests.get()
res = requests.get("http://naver.com")네이버에 get 요청을 보낸다.
status_code
print("응답코드 : ", res.status_code) # 200이면 정상get 요청이 잘 이루어졌는지, 확인할 수 있다. 200번이 출력되면 정상이라는 뜻 ( 그 외에 오류는 403 같은 것이 존재)
requests.codes.ok
요청이 잘 되었다. (200)라는 의미를 갖고있어서 이것을 이용해서
if res.status_code == requests.codes.ok:
print("정상입니다.")
else:
print("문제가 생겼습니다. [에러코드 ", res.status_code, "]")요청이 잘 되었을 경우에 if문과 else문을 통해서 코딩을 할 수 있다.
raise_for_status
res.raise_for_status()스크립트를 하기위해서 올바로 html문서를 갖겨왔다! 맞으면 ok, 아니면 오류 위에 코딩보다 더 짧게 같은 동작을 수행
정규식
import rere라는 정규식 모듈을 사용
compile
re.compile("원하는 형태")
p = re.compile("ca.e")처음 정규식을 compile을 통해 지정을 한다.
# . (ca.e): 하나의 문자를 의미 care, cafe (o) | caffe는 (x)
# ^ (^de) : 문자열의 시작을 의미, de로 시작하는 문자열 desk, destination (o) | fade(x)
# $ (se$) : 문자열의 끝 case, base (o) | face (x)
match
m = p.match("비교할 문자열 ")
m = p.match("case")정규식과 비교할 문자열이 처음부터 일치하는지 확인, 뒤에는 뭐가 오든 상관없음
단, 정규식과 맞기 않는 경우에 오류가 난다.
def print_match(m):
# 이렇게 사용하면 오류가 나지 않고 계속 프로그램을 사용할 수 있다.
if m:
print("m.group() :", m.group()) # 일치하는 문자열 반환
print("m.string :", m.string) # 입력받은 문자열 반환
print("m.start :", m.start()) # 일치하는 문자열의 시작 index
print("m.end :", m.end()) # 일치하는 문자열의 끝 index
print("m.span :", m.span()) # 일치하는 문자열의 시작과 끝 index
else:
print("매칭되지 않음 ")오류를 방지하기위해 이런식으로 사용할 수 있다.
match된 값을 호출하는 방법도 다양하다. group, string 등등 상황에 맞는 것을 사용하면 된다.
search
m = p.search("비교할 문자열"):
정규식과 비규할 문자열 중에 일치하는게 있는지 확인
findall
lst = p.findall("비교할 문자열")
lst = p.findall("cafe2care")정규식과 비교할 문자열이 일치하는 모든 것을 리시트 형태로 반환
결과값
['cafe', 'care']
User-Agent
사이트마다 다른목적으로 들어온 컴퓨터에 대한 것은 정보를 제한 하는 경우가 많기 때문에
user-Agent를 headers 정보에 줘야지만 제대로 스크랩핑을 해올 수 있다.
what is my user agent위의 문구를 구글에 검색해보면 자신 컴퓨터의 현재 브라우저의 User-Agent의 값을 얻을 수 있다.
headers = {
"user-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
url = "http://nadocoding.tistory.com"
res = requests.get(url, headers=headers)그 값을 requests.get() 에서 url과 headers를 같이 넣어주게 되면, 해당 url을 정상적으로 scraping 할 수 있다.
Beautifulsoup4
pip install Beautifulsoup4우선 package를 설치해야 한다.
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday.nhn"
res = requests.get(url)
res.raise_for_status() # 문제있을 경우 프로그램 종료
soup = BeautifulSoup(res.text, "lxml")scraping 할 url을 get으로 요청한뒤
해당 url의 text들을 "lxml parser"를 통해서 beautifulsoup로 만든 것
paring이란 어떤 문장을 분석하거나 문법적 관계를 해석하는 행위
ex) XML parser는 XML 문서가 XML 문법에 맞게 작성되었는지 검사
XML 문서를 읽고 해석하여 태그명, 속성명, 속성값 및 엘리먼트 내용을 분리해 주는 프로그램
인터넷에 주어진 정보를 내가 원하는대로 가공하여 서버에서 원하는 때 불러올 수 있도록 하는 것
Parser는 paring을 하는 프로그램이다.
출처: https://na27.tistory.com/230 [na27]
print(soup.title) #title의 전체 태그를 스크랩핑
print(soup.title.get_text()) #title 태그의 원소값만 스크랩핑
print(soup.a) # 스크랩핑 해온 html에서 맨 처음 나오는 a element를 가져와
print(soup.a.attrs) # a element 의 속성 정보를 가져옮
print(soup.a["href"]) # a element 의 href 속성에 대한 값만 가져옮
print(soup.find("a", attrs={"class": "Nbtn_upload"}))
# find는 뒤에 조건에 해당되는 것들 중에서 맨 처음에 있는 것을 가져온다.
# class": "Nbtn_upload 인 a element
print(soup.find(attrs={"class": "Nbtn_upload"}))
# class": "Nbtn_upload가 중복되는게 없다면, 태그도 생략가능하다.
print(soup.find("li", attrs={"class": "rank01"}))
rank1 = soup.find("li", attrs={"class": "rank01"})
print(rank1.a)
naver webtoon의 제목을 scraping하는 예제
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday.nhn"
res = requests.get(url)
res.raise_for_status() # 문제있을 경우 프로그램 종료
soup = BeautifulSoup(res.text, "lxml")
# 네이버 웹툰 목록 전체 가져오기
cartoons = soup.find_all("a", attrs={"class": "title"})
# find_all : class가 title인 모든 "a" element를 반환
for cartoon in cartoons:
print(cartoon.get_text())
우선 scraping 하고 싶은 url을 requests.get()으로 요청한다.
rasise_for_status()로 문제가 있는지 없는지 체크후
lxml을 통해서 pasing 작업을 한다. (사용할 수 있도록 가공한다.)
find_all()
cartoons = soup.find_all("a", attrs={"class": "title"})find_all( element, 속성)은 속성 조건에 맞는 모든 element를 반환한다.
해당 url에서 모든 title class를 가진 a태그를 cartoons에 불러온다

검사("F12")를 통해서 불러오고 싶은 정보의 element나 속성 값을 알아낼 수 있다.
get_text()
for cartoon in cartoons:
print(cartoon.get_text())불러온 모든 a태그들을 하나씩 꺼내어, get_text()를 통해서 text 값만 가져와서 출력
webtoon의 평점구해서 평균 구하기 예제
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/list.nhn?titleId=648419&weekday=mon"
res = requests.get(url)
res.raise_for_status() # 문제있을 경우 프로그램 종료
soup = BeautifulSoup(res.text, "lxml")
total_rates = 0
cartoons = soup.find_all("div", attrs={"class": "rating_type"})
for cartoon in cartoons:
rate = cartoon.find("strong").get_text()
print(rate)
# 최근 만화 10개에 대한 평균 평점
total_rates += float(rate) # 지금 평점은 sting상태라서
print("점체 점수 : ", total_rates)
print("평균 점수 : ", total_rates / len(cartoons))
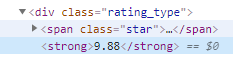
검사를 해보면, 평점은 div 태그에 class 이름은 rating_type , 그리고 평점 값은 strong 태그로 감싸져있는 것을 볼 수 있다.
그 것을 가져오기 위한 코드가
cartoons = soup.find_all("div", attrs={"class": "rating_type"})
for cartoon in cartoons:
rate = cartoon.find("strong").get_text()이렇게 되는 것이고,
전체 평점의 평균을 구하기 위해서는 ,
total_rates = 0
cartoons = soup.find_all("div", attrs={"class": "rating_type"})
for cartoon in cartoons:
rate = cartoon.find("strong").get_text()
print(rate)
total_rates += float(rate) # 지금 평점은 sting상태라서
print("점체 점수 : ", total_rates)
print("평균 점수 : ", total_rates / len(cartoons))전체 평점을 넣기 위한 total_rates라는 변수를 지정해주고, 여기에 하나씩 rate 점수를 넣고
마지막에 전체 평점수, 즉 len(cartoons)로 나눠주면 평점 평균을 구할 수 있다.
coupang에서 정보 가져오기 (1개 페이지)
import requests
import re
from bs4 import BeautifulSoup
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page=5&rocketAll=false&searchIndexingToken=1=4&backgroundColor="
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
앞과 동일하게, 해당 url을 가져오고 쿠팡에서는 headers에 User-Agent를 설정해주지 않으면, scraping을 못하게 되있기 때문에 headers를 지정해준다.

coupang에서 상품정보는 li태그로 하나씩 묵여있고, class의 이름은 search-product로 시작하는 이름으로 통일 되어있다.
하지만, 뒤에는 다른 글자가 붙는 경우가 있기 때문에, 이것을 다 불러오기 위해서 정규식을 이용한다.
items = soup.find_all("li", attrs={"class": re.compile("^search-product")})re 모듈을 통해서 re.compile("^search-product")를 해주게 되면, "^"가 search-product로 시작하는 문자열을
의미하게 되므로 원하는 정규식을 만들 수 있게 된다.
그러면, 목록별로 모든 아이템의 정보들이 items에 들어갔으니 이것을 각 이름, 가격, 리뷰등을 꺼내오기 위해서
for item in items:
# 무료배송인 것 만 보고싶을 경우
delivery_type = item.find(
"span", attrs={"class": re.compile("^badge badge-delivery")})
if delivery_type:
print("무료배송")
continue
name = item.find("div", attrs={"class": "name"}).get_text()
# 애플 제품 제외
if "Apple" in name:
print("애플 상품 제외")
continue
price = item.find("strong", attrs={"class": "price-value"}).get_text()
# 리뷰 100개 이상, 평점 4.5 이상 되는 것만 조회
rate = item.find("em", attrs={"class": "rating"})
if rate:
rate = rate.get_text()
else:
print(" <평점 없는 상품 제외합니다>")
rate_cnt = item.find(
"span", attrs={"class": "rating-total-count"})
if rate_cnt:
rate_cnt = rate_cnt.get_text() # (26)
rate_cnt = int(rate_cnt[1:-1])
else:
print(" <평점 수 없는 상품 제외합니다>")
if float(rate) >= 4.5 and rate_cnt >= 100:
print(name, price, rate, rate_cnt)그 중에서도 무료배송이 되는 것만 따로보고 싶을 경우에는
delivery_type = item.find(
"span", attrs={"class": re.compile("^badge badge-delivery")})
if delivery_type:
print("무료배송")
continue이런 식으로 if문을 사용해서 무료배송이 있는 조건으로 scraping을 했을 때 조건을 만족하는 경우에 출력을 하는 식으로 해줄 수 도 있다.
그 밖에 예외처리는
rate = item.find("em", attrs={"class": "rating"})
if rate:
rate = rate.get_text()
else:
print(" <평점 없는 상품 제외합니다>")
목록은 존재하지만, 평점이나, 리뷰가 없는 상품이 있을 수 도 있기 때문에 그런 경우를 위한 예외처리이다.
coupang에서 정보 가져오기 (여러개 페이지)
위에 한 방법은 한개의 페이지에 대한 정보를 가져오는 경우인데, 이것을 여러 페이지에서 가져오고 싶은 경우에는
url을 바꿔주는 for문을 추가해서 2중 for문 처리하면 된다.
for i in range(1, 6):
print("페이지 : ", i)
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page={}&rocketAll=false&searchIndexingToken=1=4&backgroundColor=".format(
i)
coupang에서는 페이징을 할 때에 get방식으로 url을 통해서 page=2 이런 식으로 처리하고 있다.
그렇기 때문에 "page={}".format(i)" 이런 식으로 처리해주게 되면, for문이 돌아가면서 해당하는 page에 대한 scraping이 가능해 진다.
위에서한 예제를 이 아래에 붙히면 여러개에 대한 페이지에 정보를 가져올 수 있다.
daum movie의 이미지 가져오기
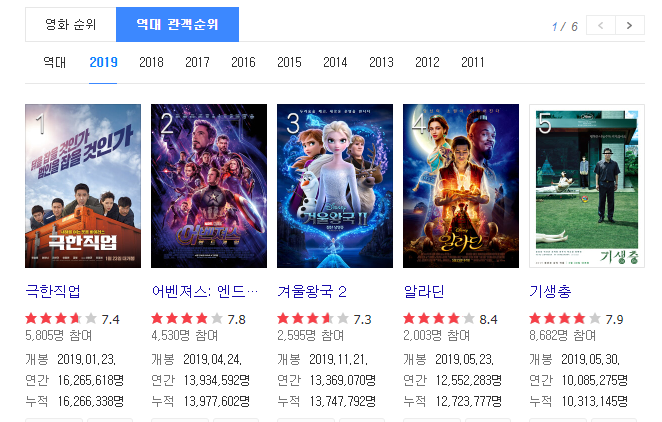
daum의 영화 순위를 보게되면 , 역대 관객순위별로, 연도별로 볼 수 있다.
여기서 15년도부터 19년도 까지의 1위부터 5위까지의 영화 포스트 이미지를 가져와서 저장하고 싶을 경우
import requests
from bs4 import BeautifulSoup
for year in range(2015, 2020):
url = "https://search.daum.net/search?w=tot&q={}%EB%85%84%EC%98%81%ED%99%94%EC%88%9C%EC%9C%84&DA=MOR&rtmaxcoll=MOR".format(
year)
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")처음 역시나 해당 url에 대한 정보를 get()요청과 BeautifulSoup()을 통한 스크랩핑을 할 수있는 환경을 만든다.
이것도 coupang에 경우와 마찬가지로, 연도별로 url이 get형식으로 데이터가 변하기 때문에 그것을 처리해주기 위한 for문을 사용한다.

img파일은 img태그에 class thumb_img로 되어있다.
images = soup.find_all("img", attrs={"class": "thumb_img"})이 내용을 다 불러온다.
for idx, image in enumerate(images):
# print(image["src"])
image_url = image["src"]
if image_url.startswith("//"):
image_url = "https:" + image_url
# print(image_url)
image_res = requests.get(image_url)
image_res.raise_for_status()
with open("movie_{}_{}.jpg".format(year, idx+1), "wb",) as f: # wb : 이미지는 글자가 아니니까 바이너리 지정
f.write(image_res.content)
if idx >= 4: # 상위 5개 이미지까지만 다운로드
break불러온 img태그에 대한 내용중에서 src에 대한 정보만을 가져오고, 이 src는 https:가 빠진 불안전한 주소이기 때문에
완전한 주소로 만들어준다.
image_url = image["src"]
if image_url.startswith("//"):
image_url = "https:" + image_url
그리고 다시 한번 이 주소로 들어가서 작업을 해줘야 한다.
image_res = requests.get(image_url)
image_res.raise_for_status()처음에 했던 것과 마찬가지로
get()요청을 통해서 이미지의 src 주소를 요청한다 .
with open("movie_{}_{}.jpg".format(year, idx+1), "wb",) as f: # wb : 이미지는 글자가 아니니까 바이너리 지정
f.write(image_res.content)그리고 파일에 저장
if idx >= 4: # 상위 5개 이미지까지만 다운로드
break
1~5위까지의 포스터만 가져오기 때문에 idx가 4까지 수행후에 break로 for문을 빠져나오게 된다.
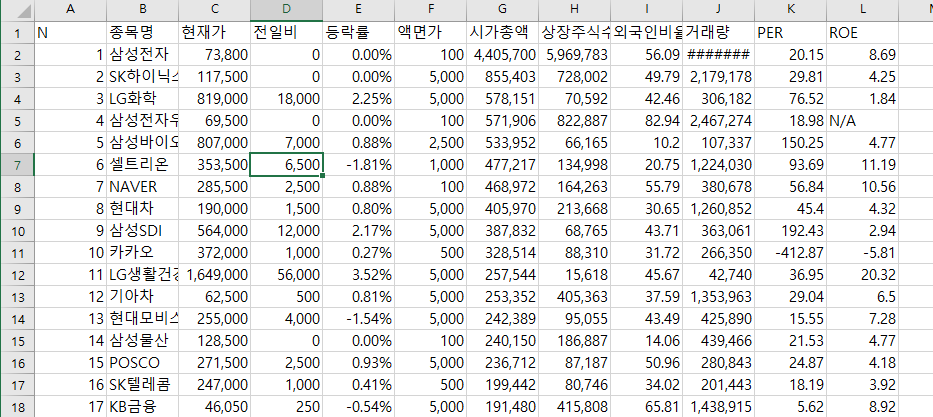
주식정보를 csv파일로 저장하기 예제
네이버에 코스피 시가총액 순위를 검색하면
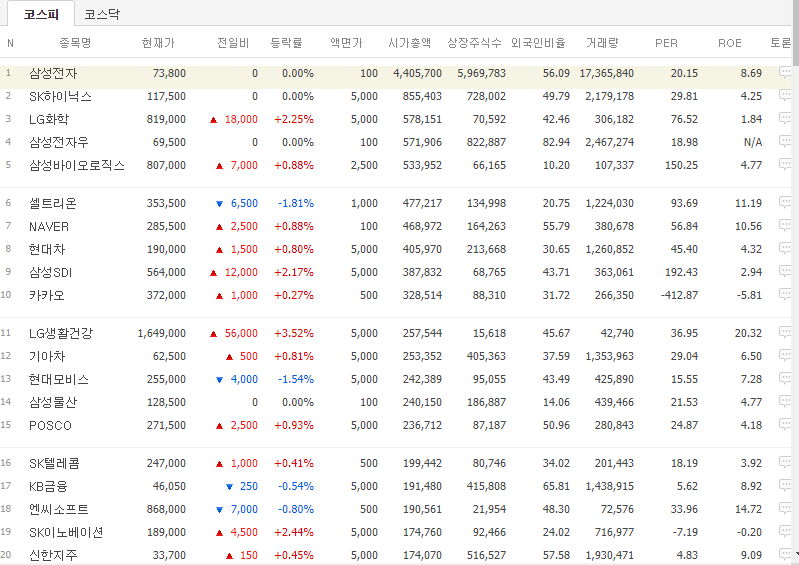
이렇게 나온다.
csv파일로 하기 위해서는 우선 import로 csv를 불러와야한다.
import csv
filename = "시가총액1-200.csv"
# newline을 공백으로 안해주면 자동으로 줄바꿈이 남
f = open(filename, "w", encoding="utf-8-sig", newline="")
# newline="" 리스트마다 줄바꿈되는것을 막는다
# utf-8-sig 엑셀파일에서 한글이 깨지는 것을 막기 위함
writer = csv.writer(f)newline = ""는 나중에 리스트를 하나씩 넣어줄 때, 줄바꿈이 되는 것을 막기 위함
utf-8-sig는 엑셀에서 파일을 열었을 때 한글이 깨지는 것을 막기 위함.
csv.witer()을 통해서 객체를 생성해서 csv 파일을 쓸 준비를 한다.
title = "N 종목명 현재가 전일비 등락률 액면가 시가총액 상장주식수 외국인비율 거래량 PER ROE".split("\t")
writer.writerow(title)우선 맨위에 title 항목을 넣어준다.
or page in range(1, 5):
res = requests.get(url + str(page))
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
data_rows = soup.find("table", attrs={"class": "type_2"})\
.find("tbody").find_all("tr")
for row in data_rows:
columns = row.find_all("td")
if len(columns) <= 1: # 의미 없는 데이터 스킵
continue
data = [column.get_text().strip() for column in columns]
# print(data)
writer.writerow(data) # list형태로 집어넣는다.
우선은 검사로 위치를 가져올 내용의 위치를 찾는다.

우선 전체적인 테이블 태그, class는 type_2 라는 이름안에

tbody 태그 안에 tr 태그 그리고 td태그 까지 들어가야 원하는 정보가 들어있다.
그것을 코딩으로 했을 때가 아래의 코딩이 된다.
for page in range(1, 5):
res = requests.get(url + str(page))
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
data_rows = soup.find("table", attrs={"class": "type_2"})\
.find("tbody").find_all("tr")
for row in data_rows:
columns = row.find_all("td")
하지만,

tr태그에는 그저 공간을 넣기위한 목적으로 데이터는 비어있는 tr태그가 존재한다. 이것을 가져오는 것을 막기위해서
if len(columns) <= 1: # 의미 없는 데이터 스킵
continue이렇게 코딩을 추가한다. columns가 1보다 작을 때, 즉 "td" 태그에 데이터가 들어있는 경우가 아닌 , 단지 공간을 위한 빈 td태그인 경우에는 건너뛰기 위한 코딩
data = [column.get_text().strip() for column in columns]그리고 get_text()로 가져온 값을 확인해보면 \n\n\n\n 이런 식으로 탈출문자들이 다 포함된 채로 가져오는걸 알 수 있다.
그것을 제외하고 뽑아오기 위해서 strip()을 이용한다.
strip([chars]) : 인자로 전달된 문자를 String의 왼쪽과 오른쪽에서 제거합니다
writer.writerow(data)가져온 data를 writer 객체에 writerow() 를 통해서 list 형태로 값을 넣어주게 되면 파일이 만들어 진다.
csv 파일
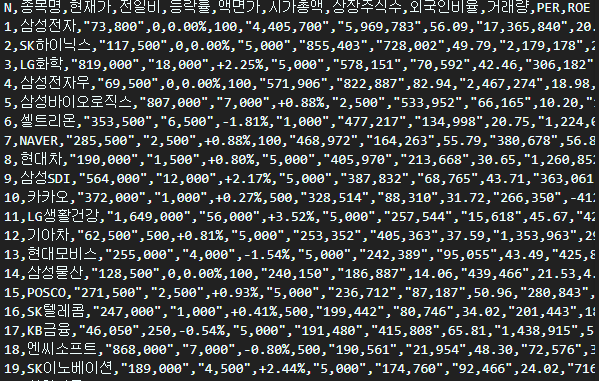
엑셀로 오픈
selenum
slenium은 웹페이지 테스트 자동화를 할 수 있는 유용한 프레임 워크
사용하기 위해선 우선 package를 설치해야한다 .
pip install selenium
그리고 webdriver도 설치해야한다.
chrome을 사용해서 할꺼니까 chrome에 chrome driver을 검색하면 다운받을 수 있는 사이트가 나온다.
단, 다운 받을 때 현재 chrome버전과 맞는 것을 다운해야한다.
chrome://versionchrome의 버전을 확인하는 방법은 주소창에 위에 주소를 입력하면 확인 가능하다.
browser를 실행시키기 위해서는
browser = webdriver.Chrome()
browser.get("http://naver.com")Chrme webdriver 객체를 생성을 하고, 그 browser에서 url로 이동하는 것
element 찾기
elem = browser.find_element_by_class_name("link_login")BeautifulSoup에서 find처럼 find_element_by_ 를 이용해서 element 를 찾는다.

그 떄에 사용되는 문법은 위에 사진대로 있다.
검색창에 입력하고 검색하고 싶을 때
elem = browser.find_element_by_id("query")우선 검색창에 위치를 검사창으로 찾아서 지정해준다
send_keys() 글자입력
elem.send_keys("일본취업")검색하는 법 (클릭, 엔터)
send_keys(Keys.ENTER)
elem.send_keys(Keys.ENTER)위의 방법은 키보드의 엔터의 역할을 한다. 사용하기 위해서는 일단 import가 필요하다.
from selenium.webdriver.common.keys import Keysclick()
elem.click()elem에는 검색 버튼을 지정해두고 그 element를 click() 하게되면 클릭이 실행된다.
get_attribute()
elem = browesr.find_elements_by_tag_name("a")
for e in elem: # a 태그의 element에서 href의 속성 값만 가져오고 싶을 때
e.get_attribute("href")elem에는 <a> 태그에 해당하는 element를 가져오고,
그 elem에서 하나씩 a태그에 관한 것을 가져온다음에 href의 속성 값만 가져오고 싶을 경우에는
get_attribute("href")를 사용한다.
bs4에서는 elem["href"]로 사용했었다.
browser 종료
browser.close()
browser.quit()close(), quit()로 종료할 수 있지만, 두개의 차이점은
close()는 현재 browser만 종료
quit()는 전체 browser 종료
selenium을 이용해서 네이버 로그인
우선 아이디, 비밀번호, 로그인 버튼의 위치를 검사창으로 찾아야한다.
browser.find_element_by_id("id").send_keys("bill1224")
browser.find_element_by_id("pw").send_keys("cldhjwld")id창은 id의 이름이 id인 element니까 거기에 send_keys()를 이용해서 아이디를 적는다.
pw창은 id의 이름이 pw인 element니까 거기에 send_keys()를 이용해서 비밀번호를 적는다.
browser.find_element_by_id("log.login").click()그리고 id이름이 log.login 인 element를 click()하면 로그인 완료
만약에 아이디를 잘 못입력했을 경우
browser.find_element_by_id("id").clear() # 기존에 적혀있는 id 초기화
browser.find_element_by_id("id").send_keys("my_id")
clear()를 이용해서 적은 id를 초기화 시킨다음 다시 send_keys()를 이용해서 아이디를 적는다
clear()를 하지않으면, 기존 id가 남아있어서 거기에 추가로 덧붙히게 된다.
html 정보출력page_source
print(browser.page_source)page_source를 사용하게되면 현재 페이지의 모든 html 태그를 가져온다.
maximize_window
browser = webdriver.Chrome()
browser.maximize_window() browser를 실행할때 창을 최대화 시켜주는 기능
네이버 항공에서 가는날짜, 돌아오는 날짜, 장소 입력후 비행기정보 가져오기
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.maximize_window() # 창 최대화
url = "https://flight.naver.com/flights/"
browser.get(url) # url로 이동
# 가는날 선택 클릭
browser.find_element_by_link_text("가는날 선택").click()
# 이번달 27일, 다음달 28일 선택
browser.find_elements_by_link_text("27")[0].click() # [0] -> 이번달 달력
browser.find_elements_by_link_text("28")[1].click() # [0] -> 이번달 달력
# 제주도 선택
browser.find_element_by_xpath(
"//*[@id='recommendationList']/ul/li[1]").click()
# 항공권 검색 클릭
browser.find_element_by_link_text("항공권 검색").click()
# time.sleep(3) #검색하고 나서 로딩이 있기 때문에, 바로 가져올 수가 없기 때문에 offset을 준다
# sleep보다 더 좋은, 이 element가 나올 때까지 기달려! 라는 설정을 할 수 있다.
try:
elem = WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located(
(By.XPATH, "//*[@id='content']/div[2]/div/div[4]/ul/li[1]")))
# 성공했을 때 동작 수행
print(elem.text) # 첫번째 결과 출력
finally:
# 동작 수행이 끝나거나, 오류났을 경우에는 browser 종료
browser.quit()
# browser를 10초까지 기달린다. 어떤 것을?? XPath란 조건으로 //*[@id='content']/div[2]/div/div[4]/ul/li[1]값이 해당하는
# element값을 기달려라 라는 의미다
# XPATH 이외에도 ID, CLASS_NAME, LINK_TEXT 등 사용가능
# 가는날 선택 클릭
browser.find_element_by_link_text("가는날 선택").click()
가는날 선택이라는 button을 클릭하면 달력이 나와서 원하는 날짜를 클릭해서 선택하는 방식이다.
따라서 우선, "가는날 선택" 이라는 text의 button을 클릭
browser.find_elements_by_link_text("27")[0].click()
browser.find_elements_by_link_text("28")[1].click() 그러면, 검사창을 열어서 확인해보면, 이번달 부터, 차례대로 달력이 날짜별로 text로 되어있는데,
순서대로 가져오기 때문에 인덱스[0]는 당연히 이번달을 의미하고 [1]은 다음달을 의미한다
그래서 이번달 27일 출국, 다음달 28일 귀국이라는 의미가 된다.
browser.find_element_by_xpath(
"//*[@id='recommendationList']/ul/li[1]").click()목적지는 제주도로 하기위해서, 제주도에 해당하는 것을 검사창에 찾은뒤 xpath를 copy해서
xpath로 검색후, click() 클릭한다.
browser.find_element_by_link_text("항공권 검색").click()그 다음 "항공권 검색"이라는 button을 click() 클릭하면, 조건에 맞는 비행기정보의 데이터를 보여준다.
조건에 맞는 데이터중에서 맨위에있는 비행기 정보를 가져오고 싶을 때, 그 위치를 검사창에서 찾아보면
//*[@id='content']/div[2]/div/div[4]/ul/li[1]위의 위치가 되는데, 검색을 누르면 로딩이 있고 로딩후에 정보가 나온다 .
그런 상황에서 문제점은, 코딩은 순서대로 코딩을 동작시키때문에 코딩대로라면 컴퓨터는 항공권 검색을 누르고 ,
바로 데이터를 가져올려고 한다.
하지만, 실제로는 로딩후에 정보가 나오기 때문에 바로 데이터를 가져올 수 없다.
그래서 딜레이를 줘야하는데, 방법으로는 2가지가 있다.
첫번째가 time 모듈을 사용해서 sleep()으로 딜레이를 주는 방식이 있다.
하지만 이 방법의 문제점은, 로딩이 얼마나 걸릴지를 모르는 상황에서는 비효율적인 방식이 될 수 있다. (로딩은 1초인데 sleep을 10초를 주면 9초는 낭비)
이것을 보완한 방법은, selenium의 expected_coditions라는 모듈을 사용해서 내가 원하는 element가 나오면 그 때 동작할 수 있도록 도와주는 기능이 있다.
elem = WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located(
(By.XPATH, "//*[@id='content']/div[2]/div/div[4]/ul/li[1]")))위의 코딩은 browser를 최대 10초까지 기달리는데, 어떤 것을 기달리냐면 뒤에 나오는 By.XPATH, 즉 xpath가
//*[@id='content']/div[2]/div/div[4]/ul/li[1]가 나올때 까지 기다린다는 의미다.
이 코딩을 사용하게 되면, 로딩이 끝나고 나서 정보가 나오게 되면, 그 때 이 코딩이 실행이되어서 맨위의 비행기정보를 가져올 수 있다.
try:
elem = WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located(
(By.XPATH, "//*[@id='content']/div[2]/div/div[4]/ul/li[1]")))
# 성공했을 때 동작 수행
print(elem.text) # 첫번째 결과 출력
finally:
# 동작 수행이 끝나거나, 오류났을 경우에는 browser 종료
browser.quit()그리고 오류를 대비해서, try문을 사용한다.
오류 없이 위의 동작이 실행 되었을 경우에는 elem.text를 통해서 결과를 출력시키고 finally를 통해서 browser를 종료
실패했을 경우에는, 아무런 동작도 하지말고 finally로 browser 종료.
참고자료 <youtube : 나도코딩>
www.youtube.com/watch?v=yQ20jZwDjTE&t=4718s&ab_channel=%EB%82%98%EB%8F%84%EC%BD%94%EB%94%A9
'IT 공부 > python' 카테고리의 다른 글
| [ python ] 자동 이메일 프로젝트 (0) | 2020.12.26 |
|---|---|
| [ python ] email 자동화 (0) | 2020.12.26 |
| [ python ] 화면 스크린샷 (0) | 2020.12.13 |
| [ python ] Tkinter project (0) | 2020.12.11 |
| [ python ] 프로젝트 starcraft 개인공부 (0) | 2020.12.09 |
Web Scraping
어느 웹사이트에서 원하는 정보를 가져오고 싶을 경우에 사용한다.
XPath
Scrabping을 할 때, 해당 url에는 많은 양에 태그들이 존재하기 때문에 비슷하고 겹치는 element가 존재한다
그 경우에, 어떤 것을 지칭하는지를 명확하게 하기 위해서 XPath를 사용한다.
/html/body/div/span/....
이런식으로 태그를 따라들어가야 하는데,
//*[@id="login"]
//*[@id="search_btn"]/span[2]
이렇게 간단하게 사용할 수 있다.
/는 현재 위치하는 것으로부터 한단계 아래있는 곳을 의미
//는 현재 위치로부터 모든 하위 엘리먼트를 의미
*은 엘리먼트 이름 상관없이 전부를 의미한다.
requests
pip install requests
우선 requests를 사용하기 위해서는 package를 설치해야 한다.
resquests.get()
res = requests.get("http://naver.com")네이버에 get 요청을 보낸다.
status_code
print("응답코드 : ", res.status_code) # 200이면 정상get 요청이 잘 이루어졌는지, 확인할 수 있다. 200번이 출력되면 정상이라는 뜻 ( 그 외에 오류는 403 같은 것이 존재)
requests.codes.ok
요청이 잘 되었다. (200)라는 의미를 갖고있어서 이것을 이용해서
if res.status_code == requests.codes.ok:
print("정상입니다.")
else:
print("문제가 생겼습니다. [에러코드 ", res.status_code, "]")요청이 잘 되었을 경우에 if문과 else문을 통해서 코딩을 할 수 있다.
raise_for_status
res.raise_for_status()스크립트를 하기위해서 올바로 html문서를 갖겨왔다! 맞으면 ok, 아니면 오류 위에 코딩보다 더 짧게 같은 동작을 수행
정규식
import rere라는 정규식 모듈을 사용
compile
re.compile("원하는 형태")
p = re.compile("ca.e")처음 정규식을 compile을 통해 지정을 한다.
# . (ca.e): 하나의 문자를 의미 care, cafe (o) | caffe는 (x)
# ^ (^de) : 문자열의 시작을 의미, de로 시작하는 문자열 desk, destination (o) | fade(x)
# $ (se$) : 문자열의 끝 case, base (o) | face (x)
match
m = p.match("비교할 문자열 ")
m = p.match("case")정규식과 비교할 문자열이 처음부터 일치하는지 확인, 뒤에는 뭐가 오든 상관없음
단, 정규식과 맞기 않는 경우에 오류가 난다.
def print_match(m):
# 이렇게 사용하면 오류가 나지 않고 계속 프로그램을 사용할 수 있다.
if m:
print("m.group() :", m.group()) # 일치하는 문자열 반환
print("m.string :", m.string) # 입력받은 문자열 반환
print("m.start :", m.start()) # 일치하는 문자열의 시작 index
print("m.end :", m.end()) # 일치하는 문자열의 끝 index
print("m.span :", m.span()) # 일치하는 문자열의 시작과 끝 index
else:
print("매칭되지 않음 ")오류를 방지하기위해 이런식으로 사용할 수 있다.
match된 값을 호출하는 방법도 다양하다. group, string 등등 상황에 맞는 것을 사용하면 된다.
search
m = p.search("비교할 문자열"):
정규식과 비규할 문자열 중에 일치하는게 있는지 확인
findall
lst = p.findall("비교할 문자열")
lst = p.findall("cafe2care")정규식과 비교할 문자열이 일치하는 모든 것을 리시트 형태로 반환
결과값
['cafe', 'care']
User-Agent
사이트마다 다른목적으로 들어온 컴퓨터에 대한 것은 정보를 제한 하는 경우가 많기 때문에
user-Agent를 headers 정보에 줘야지만 제대로 스크랩핑을 해올 수 있다.
what is my user agent위의 문구를 구글에 검색해보면 자신 컴퓨터의 현재 브라우저의 User-Agent의 값을 얻을 수 있다.
headers = {
"user-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
url = "http://nadocoding.tistory.com"
res = requests.get(url, headers=headers)그 값을 requests.get() 에서 url과 headers를 같이 넣어주게 되면, 해당 url을 정상적으로 scraping 할 수 있다.
Beautifulsoup4
pip install Beautifulsoup4우선 package를 설치해야 한다.
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday.nhn"
res = requests.get(url)
res.raise_for_status() # 문제있을 경우 프로그램 종료
soup = BeautifulSoup(res.text, "lxml")scraping 할 url을 get으로 요청한뒤
해당 url의 text들을 "lxml parser"를 통해서 beautifulsoup로 만든 것
paring이란 어떤 문장을 분석하거나 문법적 관계를 해석하는 행위
ex) XML parser는 XML 문서가 XML 문법에 맞게 작성되었는지 검사
XML 문서를 읽고 해석하여 태그명, 속성명, 속성값 및 엘리먼트 내용을 분리해 주는 프로그램
인터넷에 주어진 정보를 내가 원하는대로 가공하여 서버에서 원하는 때 불러올 수 있도록 하는 것
Parser는 paring을 하는 프로그램이다.
출처: https://na27.tistory.com/230 [na27]
print(soup.title) #title의 전체 태그를 스크랩핑
print(soup.title.get_text()) #title 태그의 원소값만 스크랩핑
print(soup.a) # 스크랩핑 해온 html에서 맨 처음 나오는 a element를 가져와
print(soup.a.attrs) # a element 의 속성 정보를 가져옮
print(soup.a["href"]) # a element 의 href 속성에 대한 값만 가져옮
print(soup.find("a", attrs={"class": "Nbtn_upload"}))
# find는 뒤에 조건에 해당되는 것들 중에서 맨 처음에 있는 것을 가져온다.
# class": "Nbtn_upload 인 a element
print(soup.find(attrs={"class": "Nbtn_upload"}))
# class": "Nbtn_upload가 중복되는게 없다면, 태그도 생략가능하다.
print(soup.find("li", attrs={"class": "rank01"}))
rank1 = soup.find("li", attrs={"class": "rank01"})
print(rank1.a)
naver webtoon의 제목을 scraping하는 예제
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday.nhn"
res = requests.get(url)
res.raise_for_status() # 문제있을 경우 프로그램 종료
soup = BeautifulSoup(res.text, "lxml")
# 네이버 웹툰 목록 전체 가져오기
cartoons = soup.find_all("a", attrs={"class": "title"})
# find_all : class가 title인 모든 "a" element를 반환
for cartoon in cartoons:
print(cartoon.get_text())
우선 scraping 하고 싶은 url을 requests.get()으로 요청한다.
rasise_for_status()로 문제가 있는지 없는지 체크후
lxml을 통해서 pasing 작업을 한다. (사용할 수 있도록 가공한다.)
find_all()
cartoons = soup.find_all("a", attrs={"class": "title"})find_all( element, 속성)은 속성 조건에 맞는 모든 element를 반환한다.
해당 url에서 모든 title class를 가진 a태그를 cartoons에 불러온다
검사("F12")를 통해서 불러오고 싶은 정보의 element나 속성 값을 알아낼 수 있다.
get_text()
for cartoon in cartoons:
print(cartoon.get_text())불러온 모든 a태그들을 하나씩 꺼내어, get_text()를 통해서 text 값만 가져와서 출력
webtoon의 평점구해서 평균 구하기 예제
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/list.nhn?titleId=648419&weekday=mon"
res = requests.get(url)
res.raise_for_status() # 문제있을 경우 프로그램 종료
soup = BeautifulSoup(res.text, "lxml")
total_rates = 0
cartoons = soup.find_all("div", attrs={"class": "rating_type"})
for cartoon in cartoons:
rate = cartoon.find("strong").get_text()
print(rate)
# 최근 만화 10개에 대한 평균 평점
total_rates += float(rate) # 지금 평점은 sting상태라서
print("점체 점수 : ", total_rates)
print("평균 점수 : ", total_rates / len(cartoons))
검사를 해보면, 평점은 div 태그에 class 이름은 rating_type , 그리고 평점 값은 strong 태그로 감싸져있는 것을 볼 수 있다.
그 것을 가져오기 위한 코드가
cartoons = soup.find_all("div", attrs={"class": "rating_type"})
for cartoon in cartoons:
rate = cartoon.find("strong").get_text()이렇게 되는 것이고,
전체 평점의 평균을 구하기 위해서는 ,
total_rates = 0
cartoons = soup.find_all("div", attrs={"class": "rating_type"})
for cartoon in cartoons:
rate = cartoon.find("strong").get_text()
print(rate)
total_rates += float(rate) # 지금 평점은 sting상태라서
print("점체 점수 : ", total_rates)
print("평균 점수 : ", total_rates / len(cartoons))전체 평점을 넣기 위한 total_rates라는 변수를 지정해주고, 여기에 하나씩 rate 점수를 넣고
마지막에 전체 평점수, 즉 len(cartoons)로 나눠주면 평점 평균을 구할 수 있다.
coupang에서 정보 가져오기 (1개 페이지)
import requests
import re
from bs4 import BeautifulSoup
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page=5&rocketAll=false&searchIndexingToken=1=4&backgroundColor="
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
앞과 동일하게, 해당 url을 가져오고 쿠팡에서는 headers에 User-Agent를 설정해주지 않으면, scraping을 못하게 되있기 때문에 headers를 지정해준다.
coupang에서 상품정보는 li태그로 하나씩 묵여있고, class의 이름은 search-product로 시작하는 이름으로 통일 되어있다.
하지만, 뒤에는 다른 글자가 붙는 경우가 있기 때문에, 이것을 다 불러오기 위해서 정규식을 이용한다.
items = soup.find_all("li", attrs={"class": re.compile("^search-product")})re 모듈을 통해서 re.compile("^search-product")를 해주게 되면, "^"가 search-product로 시작하는 문자열을
의미하게 되므로 원하는 정규식을 만들 수 있게 된다.
그러면, 목록별로 모든 아이템의 정보들이 items에 들어갔으니 이것을 각 이름, 가격, 리뷰등을 꺼내오기 위해서
for item in items:
# 무료배송인 것 만 보고싶을 경우
delivery_type = item.find(
"span", attrs={"class": re.compile("^badge badge-delivery")})
if delivery_type:
print("무료배송")
continue
name = item.find("div", attrs={"class": "name"}).get_text()
# 애플 제품 제외
if "Apple" in name:
print("애플 상품 제외")
continue
price = item.find("strong", attrs={"class": "price-value"}).get_text()
# 리뷰 100개 이상, 평점 4.5 이상 되는 것만 조회
rate = item.find("em", attrs={"class": "rating"})
if rate:
rate = rate.get_text()
else:
print(" <평점 없는 상품 제외합니다>")
rate_cnt = item.find(
"span", attrs={"class": "rating-total-count"})
if rate_cnt:
rate_cnt = rate_cnt.get_text() # (26)
rate_cnt = int(rate_cnt[1:-1])
else:
print(" <평점 수 없는 상품 제외합니다>")
if float(rate) >= 4.5 and rate_cnt >= 100:
print(name, price, rate, rate_cnt)그 중에서도 무료배송이 되는 것만 따로보고 싶을 경우에는
delivery_type = item.find(
"span", attrs={"class": re.compile("^badge badge-delivery")})
if delivery_type:
print("무료배송")
continue이런 식으로 if문을 사용해서 무료배송이 있는 조건으로 scraping을 했을 때 조건을 만족하는 경우에 출력을 하는 식으로 해줄 수 도 있다.
그 밖에 예외처리는
rate = item.find("em", attrs={"class": "rating"})
if rate:
rate = rate.get_text()
else:
print(" <평점 없는 상품 제외합니다>")
목록은 존재하지만, 평점이나, 리뷰가 없는 상품이 있을 수 도 있기 때문에 그런 경우를 위한 예외처리이다.
coupang에서 정보 가져오기 (여러개 페이지)
위에 한 방법은 한개의 페이지에 대한 정보를 가져오는 경우인데, 이것을 여러 페이지에서 가져오고 싶은 경우에는
url을 바꿔주는 for문을 추가해서 2중 for문 처리하면 된다.
for i in range(1, 6):
print("페이지 : ", i)
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page={}&rocketAll=false&searchIndexingToken=1=4&backgroundColor=".format(
i)
coupang에서는 페이징을 할 때에 get방식으로 url을 통해서 page=2 이런 식으로 처리하고 있다.
그렇기 때문에 "page={}".format(i)" 이런 식으로 처리해주게 되면, for문이 돌아가면서 해당하는 page에 대한 scraping이 가능해 진다.
위에서한 예제를 이 아래에 붙히면 여러개에 대한 페이지에 정보를 가져올 수 있다.
daum movie의 이미지 가져오기
daum의 영화 순위를 보게되면 , 역대 관객순위별로, 연도별로 볼 수 있다.
여기서 15년도부터 19년도 까지의 1위부터 5위까지의 영화 포스트 이미지를 가져와서 저장하고 싶을 경우
import requests
from bs4 import BeautifulSoup
for year in range(2015, 2020):
url = "https://search.daum.net/search?w=tot&q={}%EB%85%84%EC%98%81%ED%99%94%EC%88%9C%EC%9C%84&DA=MOR&rtmaxcoll=MOR".format(
year)
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")처음 역시나 해당 url에 대한 정보를 get()요청과 BeautifulSoup()을 통한 스크랩핑을 할 수있는 환경을 만든다.
이것도 coupang에 경우와 마찬가지로, 연도별로 url이 get형식으로 데이터가 변하기 때문에 그것을 처리해주기 위한 for문을 사용한다.
img파일은 img태그에 class thumb_img로 되어있다.
images = soup.find_all("img", attrs={"class": "thumb_img"})이 내용을 다 불러온다.
for idx, image in enumerate(images):
# print(image["src"])
image_url = image["src"]
if image_url.startswith("//"):
image_url = "https:" + image_url
# print(image_url)
image_res = requests.get(image_url)
image_res.raise_for_status()
with open("movie_{}_{}.jpg".format(year, idx+1), "wb",) as f: # wb : 이미지는 글자가 아니니까 바이너리 지정
f.write(image_res.content)
if idx >= 4: # 상위 5개 이미지까지만 다운로드
break불러온 img태그에 대한 내용중에서 src에 대한 정보만을 가져오고, 이 src는 https:가 빠진 불안전한 주소이기 때문에
완전한 주소로 만들어준다.
image_url = image["src"]
if image_url.startswith("//"):
image_url = "https:" + image_url
그리고 다시 한번 이 주소로 들어가서 작업을 해줘야 한다.
image_res = requests.get(image_url)
image_res.raise_for_status()처음에 했던 것과 마찬가지로
get()요청을 통해서 이미지의 src 주소를 요청한다 .
with open("movie_{}_{}.jpg".format(year, idx+1), "wb",) as f: # wb : 이미지는 글자가 아니니까 바이너리 지정
f.write(image_res.content)그리고 파일에 저장
if idx >= 4: # 상위 5개 이미지까지만 다운로드
break
1~5위까지의 포스터만 가져오기 때문에 idx가 4까지 수행후에 break로 for문을 빠져나오게 된다.
주식정보를 csv파일로 저장하기 예제
네이버에 코스피 시가총액 순위를 검색하면
이렇게 나온다.
csv파일로 하기 위해서는 우선 import로 csv를 불러와야한다.
import csv
filename = "시가총액1-200.csv"
# newline을 공백으로 안해주면 자동으로 줄바꿈이 남
f = open(filename, "w", encoding="utf-8-sig", newline="")
# newline="" 리스트마다 줄바꿈되는것을 막는다
# utf-8-sig 엑셀파일에서 한글이 깨지는 것을 막기 위함
writer = csv.writer(f)newline = ""는 나중에 리스트를 하나씩 넣어줄 때, 줄바꿈이 되는 것을 막기 위함
utf-8-sig는 엑셀에서 파일을 열었을 때 한글이 깨지는 것을 막기 위함.
csv.witer()을 통해서 객체를 생성해서 csv 파일을 쓸 준비를 한다.
title = "N 종목명 현재가 전일비 등락률 액면가 시가총액 상장주식수 외국인비율 거래량 PER ROE".split("\t")
writer.writerow(title)우선 맨위에 title 항목을 넣어준다.
or page in range(1, 5):
res = requests.get(url + str(page))
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
data_rows = soup.find("table", attrs={"class": "type_2"})\
.find("tbody").find_all("tr")
for row in data_rows:
columns = row.find_all("td")
if len(columns) <= 1: # 의미 없는 데이터 스킵
continue
data = [column.get_text().strip() for column in columns]
# print(data)
writer.writerow(data) # list형태로 집어넣는다.
우선은 검사로 위치를 가져올 내용의 위치를 찾는다.
우선 전체적인 테이블 태그, class는 type_2 라는 이름안에
tbody 태그 안에 tr 태그 그리고 td태그 까지 들어가야 원하는 정보가 들어있다.
그것을 코딩으로 했을 때가 아래의 코딩이 된다.
for page in range(1, 5):
res = requests.get(url + str(page))
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
data_rows = soup.find("table", attrs={"class": "type_2"})\
.find("tbody").find_all("tr")
for row in data_rows:
columns = row.find_all("td")
하지만,
tr태그에는 그저 공간을 넣기위한 목적으로 데이터는 비어있는 tr태그가 존재한다. 이것을 가져오는 것을 막기위해서
if len(columns) <= 1: # 의미 없는 데이터 스킵
continue이렇게 코딩을 추가한다. columns가 1보다 작을 때, 즉 "td" 태그에 데이터가 들어있는 경우가 아닌 , 단지 공간을 위한 빈 td태그인 경우에는 건너뛰기 위한 코딩
data = [column.get_text().strip() for column in columns]그리고 get_text()로 가져온 값을 확인해보면 \n\n\n\n 이런 식으로 탈출문자들이 다 포함된 채로 가져오는걸 알 수 있다.
그것을 제외하고 뽑아오기 위해서 strip()을 이용한다.
strip([chars]) : 인자로 전달된 문자를 String의 왼쪽과 오른쪽에서 제거합니다
writer.writerow(data)가져온 data를 writer 객체에 writerow() 를 통해서 list 형태로 값을 넣어주게 되면 파일이 만들어 진다.
csv 파일
엑셀로 오픈
selenum
slenium은 웹페이지 테스트 자동화를 할 수 있는 유용한 프레임 워크
사용하기 위해선 우선 package를 설치해야한다 .
pip install selenium
그리고 webdriver도 설치해야한다.
chrome을 사용해서 할꺼니까 chrome에 chrome driver을 검색하면 다운받을 수 있는 사이트가 나온다.
단, 다운 받을 때 현재 chrome버전과 맞는 것을 다운해야한다.
chrome://versionchrome의 버전을 확인하는 방법은 주소창에 위에 주소를 입력하면 확인 가능하다.
browser를 실행시키기 위해서는
browser = webdriver.Chrome()
browser.get("http://naver.com")Chrme webdriver 객체를 생성을 하고, 그 browser에서 url로 이동하는 것
element 찾기
elem = browser.find_element_by_class_name("link_login")BeautifulSoup에서 find처럼 find_element_by_ 를 이용해서 element 를 찾는다.
그 떄에 사용되는 문법은 위에 사진대로 있다.
검색창에 입력하고 검색하고 싶을 때
elem = browser.find_element_by_id("query")우선 검색창에 위치를 검사창으로 찾아서 지정해준다
send_keys() 글자입력
elem.send_keys("일본취업")검색하는 법 (클릭, 엔터)
send_keys(Keys.ENTER)
elem.send_keys(Keys.ENTER)위의 방법은 키보드의 엔터의 역할을 한다. 사용하기 위해서는 일단 import가 필요하다.
from selenium.webdriver.common.keys import Keysclick()
elem.click()elem에는 검색 버튼을 지정해두고 그 element를 click() 하게되면 클릭이 실행된다.
get_attribute()
elem = browesr.find_elements_by_tag_name("a")
for e in elem: # a 태그의 element에서 href의 속성 값만 가져오고 싶을 때
e.get_attribute("href")elem에는 <a> 태그에 해당하는 element를 가져오고,
그 elem에서 하나씩 a태그에 관한 것을 가져온다음에 href의 속성 값만 가져오고 싶을 경우에는
get_attribute("href")를 사용한다.
bs4에서는 elem["href"]로 사용했었다.
browser 종료
browser.close()
browser.quit()close(), quit()로 종료할 수 있지만, 두개의 차이점은
close()는 현재 browser만 종료
quit()는 전체 browser 종료
selenium을 이용해서 네이버 로그인
우선 아이디, 비밀번호, 로그인 버튼의 위치를 검사창으로 찾아야한다.
browser.find_element_by_id("id").send_keys("bill1224")
browser.find_element_by_id("pw").send_keys("cldhjwld")id창은 id의 이름이 id인 element니까 거기에 send_keys()를 이용해서 아이디를 적는다.
pw창은 id의 이름이 pw인 element니까 거기에 send_keys()를 이용해서 비밀번호를 적는다.
browser.find_element_by_id("log.login").click()그리고 id이름이 log.login 인 element를 click()하면 로그인 완료
만약에 아이디를 잘 못입력했을 경우
browser.find_element_by_id("id").clear() # 기존에 적혀있는 id 초기화
browser.find_element_by_id("id").send_keys("my_id")
clear()를 이용해서 적은 id를 초기화 시킨다음 다시 send_keys()를 이용해서 아이디를 적는다
clear()를 하지않으면, 기존 id가 남아있어서 거기에 추가로 덧붙히게 된다.
html 정보출력page_source
print(browser.page_source)page_source를 사용하게되면 현재 페이지의 모든 html 태그를 가져온다.
maximize_window
browser = webdriver.Chrome()
browser.maximize_window() browser를 실행할때 창을 최대화 시켜주는 기능
네이버 항공에서 가는날짜, 돌아오는 날짜, 장소 입력후 비행기정보 가져오기
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.maximize_window() # 창 최대화
url = "https://flight.naver.com/flights/"
browser.get(url) # url로 이동
# 가는날 선택 클릭
browser.find_element_by_link_text("가는날 선택").click()
# 이번달 27일, 다음달 28일 선택
browser.find_elements_by_link_text("27")[0].click() # [0] -> 이번달 달력
browser.find_elements_by_link_text("28")[1].click() # [0] -> 이번달 달력
# 제주도 선택
browser.find_element_by_xpath(
"//*[@id='recommendationList']/ul/li[1]").click()
# 항공권 검색 클릭
browser.find_element_by_link_text("항공권 검색").click()
# time.sleep(3) #검색하고 나서 로딩이 있기 때문에, 바로 가져올 수가 없기 때문에 offset을 준다
# sleep보다 더 좋은, 이 element가 나올 때까지 기달려! 라는 설정을 할 수 있다.
try:
elem = WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located(
(By.XPATH, "//*[@id='content']/div[2]/div/div[4]/ul/li[1]")))
# 성공했을 때 동작 수행
print(elem.text) # 첫번째 결과 출력
finally:
# 동작 수행이 끝나거나, 오류났을 경우에는 browser 종료
browser.quit()
# browser를 10초까지 기달린다. 어떤 것을?? XPath란 조건으로 //*[@id='content']/div[2]/div/div[4]/ul/li[1]값이 해당하는
# element값을 기달려라 라는 의미다
# XPATH 이외에도 ID, CLASS_NAME, LINK_TEXT 등 사용가능
# 가는날 선택 클릭
browser.find_element_by_link_text("가는날 선택").click()
가는날 선택이라는 button을 클릭하면 달력이 나와서 원하는 날짜를 클릭해서 선택하는 방식이다.
따라서 우선, "가는날 선택" 이라는 text의 button을 클릭
browser.find_elements_by_link_text("27")[0].click()
browser.find_elements_by_link_text("28")[1].click() 그러면, 검사창을 열어서 확인해보면, 이번달 부터, 차례대로 달력이 날짜별로 text로 되어있는데,
순서대로 가져오기 때문에 인덱스[0]는 당연히 이번달을 의미하고 [1]은 다음달을 의미한다
그래서 이번달 27일 출국, 다음달 28일 귀국이라는 의미가 된다.
browser.find_element_by_xpath(
"//*[@id='recommendationList']/ul/li[1]").click()목적지는 제주도로 하기위해서, 제주도에 해당하는 것을 검사창에 찾은뒤 xpath를 copy해서
xpath로 검색후, click() 클릭한다.
browser.find_element_by_link_text("항공권 검색").click()그 다음 "항공권 검색"이라는 button을 click() 클릭하면, 조건에 맞는 비행기정보의 데이터를 보여준다.
조건에 맞는 데이터중에서 맨위에있는 비행기 정보를 가져오고 싶을 때, 그 위치를 검사창에서 찾아보면
//*[@id='content']/div[2]/div/div[4]/ul/li[1]위의 위치가 되는데, 검색을 누르면 로딩이 있고 로딩후에 정보가 나온다 .
그런 상황에서 문제점은, 코딩은 순서대로 코딩을 동작시키때문에 코딩대로라면 컴퓨터는 항공권 검색을 누르고 ,
바로 데이터를 가져올려고 한다.
하지만, 실제로는 로딩후에 정보가 나오기 때문에 바로 데이터를 가져올 수 없다.
그래서 딜레이를 줘야하는데, 방법으로는 2가지가 있다.
첫번째가 time 모듈을 사용해서 sleep()으로 딜레이를 주는 방식이 있다.
하지만 이 방법의 문제점은, 로딩이 얼마나 걸릴지를 모르는 상황에서는 비효율적인 방식이 될 수 있다. (로딩은 1초인데 sleep을 10초를 주면 9초는 낭비)
이것을 보완한 방법은, selenium의 expected_coditions라는 모듈을 사용해서 내가 원하는 element가 나오면 그 때 동작할 수 있도록 도와주는 기능이 있다.
elem = WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located(
(By.XPATH, "//*[@id='content']/div[2]/div/div[4]/ul/li[1]")))위의 코딩은 browser를 최대 10초까지 기달리는데, 어떤 것을 기달리냐면 뒤에 나오는 By.XPATH, 즉 xpath가
//*[@id='content']/div[2]/div/div[4]/ul/li[1]가 나올때 까지 기다린다는 의미다.
이 코딩을 사용하게 되면, 로딩이 끝나고 나서 정보가 나오게 되면, 그 때 이 코딩이 실행이되어서 맨위의 비행기정보를 가져올 수 있다.
try:
elem = WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located(
(By.XPATH, "//*[@id='content']/div[2]/div/div[4]/ul/li[1]")))
# 성공했을 때 동작 수행
print(elem.text) # 첫번째 결과 출력
finally:
# 동작 수행이 끝나거나, 오류났을 경우에는 browser 종료
browser.quit()그리고 오류를 대비해서, try문을 사용한다.
오류 없이 위의 동작이 실행 되었을 경우에는 elem.text를 통해서 결과를 출력시키고 finally를 통해서 browser를 종료
실패했을 경우에는, 아무런 동작도 하지말고 finally로 browser 종료.
참고자료 <youtube : 나도코딩>
www.youtube.com/watch?v=yQ20jZwDjTE&t=4718s&ab_channel=%EB%82%98%EB%8F%84%EC%BD%94%EB%94%A9
'IT 공부 > python' 카테고리의 다른 글
| [ python ] 자동 이메일 프로젝트 (0) | 2020.12.26 |
|---|---|
| [ python ] email 자동화 (0) | 2020.12.26 |
| [ python ] 화면 스크린샷 (0) | 2020.12.13 |
| [ python ] Tkinter project (0) | 2020.12.11 |
| [ python ] 프로젝트 starcraft 개인공부 (0) | 2020.12.09 |